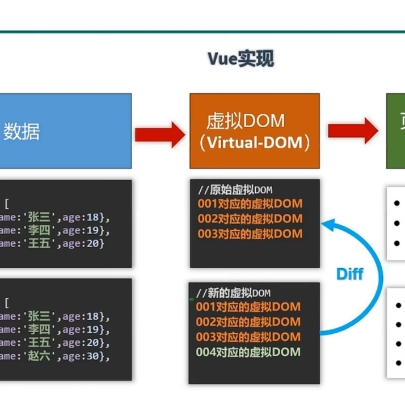
MYSQL——基础篇
MYSQL概述
MYSQL的特点
mysql数据库是用c和c++语言编写的,以保证源码的可移植性;
支持多个操作系统,例如windows、Linux、macOS等
支持多线程,可以充分利用CPU
为多种编程语言提供API,包括c语言,java,python语言
MySQL优化SQL算法,有效提高查询速度
MySQL开放源码且无版权限制,自由性强。使用成本低
MySQL历史悠久,社区及用户非常活跃,遇到问题很快获得答案
MySQL Workbench (GUI TOOL)
一款专门为MySQL设计的ER/数据库建模工具,MySQL Workbench又分为两个版本,分别为社区版(MySQL Workbench OSS)、商用版(MySQL Workbench SE)
数据库相关概念
数据库
存储数据的仓库,数据有组织的进行存储——简称DataBase(DB)
数据库管理系统
操作数据库的大型软件——简称DataBase Management System(DBMS)
SQL
操作关系型数据库的编程语言,定义了一套操作关系型数据库统一标准——简称Structured Query Language(SQL)
主流的关系型数据库管理系统
Oracle
MYSQL
Microsoft SQLServer
PostgreSQL
IBM Db2
Microsoft Access
SQLite
MariaDB
Microsoft Azure SQL Database
Hive
关系型数据库管理系统组成
数据库管理系统主要由数据库和表组成的,一个系统可以有很多个数据库,每个数据库可以有很多表
启动和停止MYSQL
快捷键WIN+R,输入services.msc
第二种方法
启动——命令行当中输入指令——net start mysql
停止——命令行当中输入指令——net stop mysql
链接数据库
在cmd中使用命令——mysql -u root -p来实现
MYSQL数据模型
关系型数据库
建立在关系模型基础上,有多张相互连接的二维表组成的数据库
优点
使用表存储数据,格式统一,便于维护
使用SQL语言操作,标准统一,使用方便
数据模型
Navicat快捷键
一、
SHIFT+CTRL+R 运行已选择的
http://www.formysql.com/jiqiao/navicat-kuaijiejian.html
二、

SQL数据库
SQL 简介
SQL (Structured Query Language:结构化查询语言) 是用于管理关系数据库管理系统(RDBMS)。 SQL 的范围包括数据插入、查询、更新和删除,数据库模式创建和修改,以及数据访问控制。
SQL 是什么?
SQL 指结构化查询语言,全称是 Structured Query Language。
SQL 让您可以访问和处理数据库,包括数据插入、查询、更新和删除。
SQL 在1986年成为 ANSI(American National Standards Institute 美国国家标准化组织)的一项标准,在 1987 年成为国际标准化组织(ISO)标准。
SQL 能做什么?
SQL 面向数据库执行查询
SQL 可从数据库取回数据
SQL 可在数据库中插入新的记录
SQL 可更新数据库中的数据
SQL 可从数据库删除记录
SQL 可创建新数据库
SQL 可在数据库中创建新表
SQL 可在数据库中创建存储过程
SQL 可在数据库中创建视图
SQL 可以设置表、存储过程和视图的权限
SQL 是一种标准 – 但是…
虽然 SQL 是一门 ANSI(American National Standards Institute 美国国家标准化组织)标准的计算机语言,但是仍然存在着多种不同版本的 SQL 语言。
然而,为了与 ANSI 标准相兼容,它们必须以相似的方式共同地来支持一些主要的命令(比如 SELECT、UPDATE、DELETE、INSERT、WHERE 等等)。
 | 注释:除了 SQL 标准之外,大部分 SQL 数据库程序都拥有它们自己的专有扩展! |
|---|---|
在您的网站中使用 SQL
要创建一个显示数据库中数据的网站,您需要:
RDBMS 数据库程序(比如 MS Access、SQL Server、MySQL)
使用服务器端脚本语言,比如 PHP 或 ASP
使用 SQL 来获取您想要的数据
使用 HTML / CSS
RDBMS
RDBMS 指关系型数据库管理系统,全称 Relational Database Management System。
RDBMS 是 SQL 的基础,同样也是所有现代数据库系统的基础,比如 MS SQL Server、IBM DB2、Oracle、MySQL 以及 Microsoft Access。
RDBMS 中的数据存储在被称为表的数据库对象中。
表是相关的数据项的集合,它由列和行组成。
SQL 语法
数据库表
一个数据库通常包含一个或多个表。每个表有一个名字标识(例如:"Websites"),表包含带有数据的记录(行)。
在本教程中,我们在 MySQL 的 RUNOOB 数据库中创建了 Websites 表,用于存储网站记录。
我们可以通过以下命令查看 "Websites" 表的数据:
5 rows in set (0.01 sec)1mysql> use RUNOOB;2Database changed3mysql> set names utf8;5Query OK, 0 rows affected (0.00 sec)6mysql> SELECT * FROM Websites;8+----+--------------+---------------------------+-------+---------+9| id | name | url | alexa | country |10+----+--------------+---------------------------+-------+---------+11| 1 | Google | https://www.google.cm/ | 1 | USA |12| 2 | 淘宝 | https://www.taobao.com/ | 13 | CN |13| 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN |14| 4 | 微博 | http://weibo.com/ | 20 | CN |15| 5 | Facebook | https://www.facebook.com/ | 3 | USA |16+----+--------------+---------------------------+-------+---------+175 rows in set (0.01 sec)
解析
use RUNOOB; 命令用于选择数据库。
set names utf8; 命令用于设置使用的字符集。
SELECT * FROM Websites; 读取数据表的信息。
上面的表包含五条记录(每一条对应一个网站信息)和5个列(id、name、url、alexa 和country)。
SQL 对大小写不敏感:SELECT 与 select 是相同的。
SQL 语句后面的分号?
某些数据库系统要求在每条 SQL 语句的末端使用分号。
分号是在数据库系统中分隔每条 SQL 语句的标准方法,这样就可以在对服务器的相同请求中执行一条以上的 SQL 语句。
在本教程中,我们将在每条 SQL 语句的末端使用分号。
一些最重要的 SQL 命令
SELECT – 从数据库中提取数据
UPDATE – 更新数据库中的数据
DELETE – 从数据库中删除数据
INSERT INTO – 向数据库中插入新数据
CREATE DATABASE – 创建新数据库
ALTER DATABASE – 修改数据库
CREATE TABLE – 创建新表
ALTER TABLE – 变更(改变)数据库表
DROP TABLE – 删除表
CREATE INDEX – 创建索引(搜索键)
DROP INDEX – 删除索引
#
SQL通用语法
SQL语句可以单行或者多行书写,以分号结尾
SQL语句可以使用空格/缩进来增强语句的可读性
MYSQL数据库的SQL语句不区分大小写,关键字建议使用大写
注释
单行注释:– 注释内容 或 #注释内容(mysql特有)
多行注释:
/* 注释内容*/
常见的图形化管理工具
Navicat
sqlyog——特别简单且简洁
MySQL workbench
DataGrip
SQL语句的分类
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definition language | 数据定义语言,用来定义数据库对象(数据库,表,字段),对数据库的常用操作,对表结构的常用操作,修改表结构 |
| DML | Data Manipulation language | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | Data Query language | 数据查询语言,用来查询数据库中表的记录 |
| DCL | Data Control language | 数据控制语言,用来创建数据库用户,控制数据库的访问权限 |
DDL语句
DDL-数据库操作
查询
查询所有数据库
SHOW DATABASES;查询当前数据库
SELECT DATABASE();
创建
CREATE DATABASE [IF NOT EXISTS]数据库名[DEFAULT CHARSET]字符集[COLLATE 排序规则];——[]里的内容都是可选的删除
DROP DATABASE[IF EXISTS]数据库名;使用
USE 数据库名;
| 功能 | SQL |
|---|---|
| 查看所有的数据库 | show databases; |
| 创建数据库 | create database [if not exists] 数据库名[charset=utf8]; |
| 切换(选择要操作的数据库)数据库 | use 数据库的名称; |
| 删除数据库 | drop database [if exists] 数据库名称; |
| 修改数据库编码 | alter database 数据库名称 character set utf8; |
DDL-表操作-查询
查询当前数据库所有表
SHOW TABLES;查询表结构
DESC表名;查询指定表的建表语句
SHOW CREATE TABLE 表名;
对表结构的常用操作-创建表-修改表
创建表
xxxxxxxxxx51create table [if not exists] 表名(2字段名1 类型[(宽度)] [约束条件] [comment '字段说明'],3字段名2 类型[(宽度)] [约束条件] [comment '字段说明'],4字段名3 类型[(宽度)] [约束条件] [comment '字段说明']5)[表的一些设置];-- 代码里的[]里的内容表示可以写也可以不写创建表实际上就是构建一张空表,指定这个表的名字,这个表有几列,每一列的名字,以及每一列存储的数据类型
xxxxxxxxxx71use mysql;-- 使用数据库并且在该数据库下新建一个名为student的表2create table if not exists student(3 id int unsigned,-- 表下的id为小整型,unsigned表示无符号4 name varchar(20),-- 名字为字符串型5 age int,6 brith date7);| 功能 | SQL |
|---|---|
| 查看当前数据库所有的表名称 | show tables; |
| 查看指定某个表的创建语句 | show create table 表名; |
| 查看表结构 | desc 表名; |
| 删除表 | drop table 表名; |
添加列
语法格式
xxxxxxxxxx11alter table 表名 add 列名 类型(长度) [约束];修改列名和类型
语法格式
xxxxxxxxxx11alter table 表名 change 旧列名 新列名 类型() 约束;修改数据类型
语法格式
xxxxxxxxxx11alter table 表名 modify 列名 新数据类型;删除列
语法格式
xxxxxxxxxx11alter table 表名 drop 列名;修改表名
语法格式
xxxxxxxxxx11rename table 表名 to 新表名;xxxxxxxxxx11alter table 表名 rename to 新的表名;d
DDL总结
| DDL语法 | 说明 |
|---|---|
| show databases; | 查询所有数据库 |
| create database 数据库名; | 创建数据库 |
| use 数据库名; | 使用数据库 |
| drop database 数据库名; | 删除数据库 |
| show tables; | 查询数据库下的所有表 |
| desc 表名; | 查看表的结构(不包括数据 |
| create table 表名(字段 数据类型) | 创建表及表的结构 |
| drop table 表名; | 删除表 |
| alter table 表名 add 列名 数据类型(); | 在表中添加列 |
| alter table 表名 modify 列名 新数据类型; | 修改列的数据类型 |
| alter table 表名 change 旧列名 新列名 数据类型(); | 修改列名 |
| alter table 表名 drop 列名; | 删除列 |
| alter table 表名 rename to 新的表名; | 修改表名 |
| rename table 表名 to 新表名 | 修改表名 |
DML操作
DML是指数据操作语言,DataManipulation Language,用来对数据库中的表的数据记录进行更新
关键字:
插入insert
删除delete
更新update
insert数据插入
语法格式——两种格式分别如下:
xxxxxxxxxx21insert into 表(列名1,列名2,列名3...)values (值1,值2,值3...);//向表中插入某些数据2insert into 表 values(值1,值2,值3...);//向表中插入所有列的数据批量插入数据
xxxxxxxxxx11insert into 表名 values(值1,值2...),(值1,值2...),...(值1,值2...);
例如:
xxxxxxxxxx141insert into student (sid,name,id)values(100,'男',10);-- 列的类型要和值一致2insert into student values(100,'男',10);3
4insert into student values5(004,'DuMu','bo',02),6(003,'WaBo','bo',01),7(004,'LiWi','bo',01),8(005,'DiuC','gr',02),9(006,'LiuB','bo',03),10(001,'GuYu','bo',03),11(002,'ZaFe','bo',03),12(003,'CaCo','bo',03),13(004,'ZoYu','bo',03),14(005,'ZGLi','bo',03);-- 这样可以同时插入多行数据数据修改
语法格式——两种方式如下
xxxxxxxxxx51-- 格式一2update 表名 set 字段名1=值,字段名2=值...;-- 将所有数据都进行修改,即同一列的值都将变成同一个3
4-- 格式二5update 表名 set 字段名1=值,字段名2=值...where 条件;-- 在选定的条件下进行数据的修改例如
xxxxxxxxxx81update book set book_name=20;-- 将表名为book中的所有book_name的值都改为202desc book;3update book set book_name=200 where book_p='页数';-- 将表中book_p的值为“页数”的所在的列里面的book_name的值改为2004
5update book set book_name=200 where book_p='页数' and book_page=20;-- 如有要同时使用多个条件则加上and进行条件的连接6update book set book_name=200 where book_p > 20;-- 范围条件7
8update book set book_name=200,book_page=100 where book_p > 100;-- 同时修改多个属性值以及附上的条件数据删除
语法格式
xxxxxxxxxx51delete from 表名 [where 条件];-- 条件是可以省略的,如果不加条件就会将整个表的数据都进行删除,和修改表里面的数据操作一样,用where进行删除指定的列的数据。2
3truncate table 表名; -- 一下子把表的内容清空,效果和不加条件的delete一样,truncate删除得更彻底4或者 5truncate 表名;delete和truncate原理不同,delete只删除内容,而truncate类似于drop table,可以理解为是将整个表删除,然后再创建该表
DML操作总结
| DML语法 | 说明 |
|---|---|
| insert into 表名(列名1,列名2,列名3…)values (值1,值2,值3…); | 向表中的对应的每一列添加一个数据 |
| insert into 表 values(值1,值2,值3…); | 可以不写列名,但写入的数据要对应列名的顺序 |
| insert into 表名 values(值1,值2…),(值1,值2…),…(值1,值2…); | 给列名下添加多个数据 |
| update 表名 set 字段名1=值,字段名2=值…; | 修改表中列里面的数据 |
| update 表名 set 字段名1=值,字段名2=值…where 条件; | 在特定的条件下修改表中列里面的数据 |
| delete from 表名 [where 条件]; | 删除表中对应的列的数据,如果没有写where就会把表里面的所有数据删除掉 |
DQL数据查询
select——字段列表
from——表名列表
where——条件列表
group by——分组列表
having——分组后条件
order by——排序字段
limit——分页限定
基础查询
查询多个字段
xxxxxxxxxx21select 字段列表 from 表名;2select * from 表名; -- 查询所有数据例:
xxxxxxxxxx31select name,age from student;-- 查询student表中name和age列里面的数据2select * from student;-- 查询student表里面所有的数据3select * from student where id=1;-- 在student表中查询id为1的学生的所有数据
去除重复记录
xxxxxxxxxx11select distinct 字段列表 from 表名;起别名
xxxxxxxxxx11AS:AS可以省略例如:
xxxxxxxxxx11SELECT addss as 地址,age as 年龄 from student;-- 给addss取别名为地址,age取别名为年龄
条件查询
条件查询语法
xxxxxxxxxx11select 字段列表 from where 条件列表;
条件运算符
| 符号 | 功能 |
|---|---|
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| = | 等于 |
| <>或!= | 不等于 |
| between…and | 在某个范围之内 |
| in(…) | 多选一 |
| like占位符 | 模糊查询,__单个任意字符 %多个任意字符 |
| is null | 是null |
| is not null | 不是null |
| and或&& | 与 |
| or或|| | 或 |
| not或! | 非 |
xxxxxxxxxx21SELECT * FROM student where name LIKE 'L%'; -- 查询首字母为L的name的信息数据2SELECT * FROM student where name LIKE '%L%'; -- 查询name里面含有L的数据信息 排序查询
排序查询语法
xxxxxxxxxx11select 字段列表 from 表名 order by 排序字段名1 [排序方式],排序字段名2 [排序方式]...;排序方式
ASC:升序排序(默认值)
DESC:降序排序
注意:如果有多个排序条件,当前边的条件值一样时,才会根据第二条件进行排序
分组查询
聚合函数分类:
概念
将一列数据作为一个整体,进行纵向计算
聚合函数分类:
| 函数名 | 功能 |
|---|---|
| count(列名) | 统计数量(一般选用不为null的列) |
| max(列名) | 最大值 |
| min(列名) | 最小值 |
| sum(列名) | 求和 |
| avg(列名) | 平均值 |
聚合函数语法:
xxxxxxxxxx11select 集合函数名(列名) from 表名;null值不参与所有聚合函数的函数运算
count:统计数量
取值
主键——非空且唯一
*——代表所有
分组查询
分组查询语法:
select 字段列表 from 表名 [where 分组前条件限定] group by 分组字段名 [having 分组后条件过滤];
分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
where和having的区别:
执行时机一样:where是分组之前进行限定,不满足where条件的,则不参与分组,而having是分组之后对结果进行过滤
可判断的条件不一样,where不能对聚合函数进行判断,having可以
执行顺序:where>聚合函数>having
xxxxxxxxxx81-- 查询男同学和女同学各自的数学平均分2select avg(math) from student group by sex;-- 这样写是不显示对应的男还是女的3select sex,avg(math) from student group by sex;-- 这样写就可以看到男同学和女同学对应的数学平均分了4-- 查询男同学和女同学各自的数学平均分和人数5select sex,avg(math),count(*) from student group by sex;6-- 查询男同学和女同学各自的数学平均分和人数,要求分数低于60分的不参与分组7select sex,avg(math),count(*) from student where math>60 group by sex;8-- 查询男同学和女同学各自的数学平均分和人数,要求分数低于60分的不参与分组,分组之后人数大于4的分页查询
分页查询的语法:
select 字段列表 from 表名 limit 开始索引 , 查询条目数;起始索引:从0开始
计算公式:起始索引=(当前页码-1)*每页显示的条数
tips:
分页查询limit是MYSQL数据库的方言
Oracle分页查询使用rownumber
SQL Server分页查询使用top
xxxxxxxxxx81-- 从0开始查询 查询3条数据2select*from student limit 0,3;3-- 每页显示3条数据,查询第一页数据4select*from student limit 0,3;5-- 每页显示3条数据,查询第二页数据6select*from student limit 3,3;7-- 每页显示3条数据,查询第三页数据8select*from student limit 6,3;DQL总结
| 语法 | 作用 |
|---|---|
| select 字段列表 from 表名; | 查询字段 |
| select * from 表名; | 查询所有数据 |
| select distinct 字段列表 from 表名; | 去除重复查询 |
| AS:AS可以省略(SELECT addss as 地址,age as 年龄 from student;) | 起别名 |
| select 字段列表 from where 条件列表; | 条件查询 |
| select 字段列表 from 表名 order by 排序字段名1 [排序方式]…;(asc:升序;desc:降序) | 排序查询 |
| select 字段列表 from 表名 [where 分组前条件限定] group by 分组字段名 [having 分组后条件过滤]; | 分组查询 |
| select 字段列表 from 表名 limit 开始索引 , 查询条目数; | 分页查询 |
| select 聚合函数名(列名) from 表名; | 聚合函数 |
数据类型
数据类型是指在创建表的时候为表中字段指定数据类型,只有数据符合类型才能存储起来,使用数据类型的原则是够用就行,尽量使用取值范围小的,而不用大的,这样可以更多的节省空间。
数值类型
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| tinyint | 1byte | -128,127 | 0,255 | 小整数值 |
| smallint | 2byte | (-32 768,32 767) | (0,65 535) | 大整数值 |
| mediumint | 3byte | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| int或inyeger | 4byte | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| bigint | 8byte | (-9 233 372 036 854 775 808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 651) | 极大整数值 |
| float | 4byte | (-3.402 823 466E+38,3.402 823 351E+38) | (0,) | 单精度浮点型 |
| double | 8byte | 双精度浮点型 | ||
| decimal | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 | |
| 次表中有黄色标注的是SQL学习中需要关注的重点数据类型 |
其中decimal(M,D)就是表示M是小数的有效位数,D为小数点后保留的位数,如decimal(5,2)就是123.45这样表示,整个小数总共有5位,小数后面保留两位。
字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| char | 0-255bytes | 定长字符串 |
| varchar | 0-65535bytes | 变长字符串 |
| tinyblob | 0-255bytes | 不超过255个字符的二进制字符 |
| tinytext | 0-255bytes | 短文本字符串 |
| blob | 0-65535bytes | 二进制形式的长文本数据 |
| text | 0-65535bytes | 长文本数据 |
| mediumblob | 0-16777215bytes | 二进制形式的中度长度文本数据 |
| mediumtext | 0-16777215bytes | 中等长度文本数据 |
| longblob | 0-4294967295bytes | 二进制形式的极大文本数据 |
| longtext | 0-4294967295bytes | 极大文本数据 |
日期类型
| 类型 | 大小 | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| date | 3 | yyyy-mm-dd | 日期值 | |
| time | 3 | hh:mm:ss | 时间值或持续时间 | |
| year | 1 | yyyy | 年份值 | |
| datetime | 8 | yyyy-mm-dd hh:mm:ss | 混合日期和时间 | |
| timestamp | 4 | yyyymmdd hhmmss | 混合日期和时间、时间戳 |
约束
概念和分类
约束的概念:
约束是作用于表中列上的规则,用于限制加入表的数据
约束的存在保证了数据库中数据的正确性,有效性和完整性
约束的分类
| 约束名称 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 保证列中所有的数据不能有null值 | NOT NULL(not null) |
| 唯一约束 | 保证列中所有数据各不相同 | UNIQUE(unique) |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | PRIMARY KEY(primary key) |
| 检查约束 | 保证列表中的值满足某一条件 | CHECK(check) |
| 默认约束 | 保存数据时,未指定值采用默认值 | DEFAULT(default) |
| 外键约束 | 外键用来让两个表的数据之间建立连接,保证数据的一致性和完整性 | FOREIGN KEY(foreign key) |
一列数据可以有多个约束,中间只需要有空格连接即可
Tips:MYSQL 不支持检查约束
添加约束案例——创建一个表,以id为主键约束,且自增长(使用auto_increment)
就是说不给id赋值,id会自己递增
xxxxxxxxxx121create table boy(2id int(8) PRIMARY KEY auto_increment unique,-- 主键自动增长3nam VARCHAR(8) not null,4age int(3) not null,5lik VARCHAR(8) not null unique,-- 默认字段是不给添加值的时候自动生效6adress VARCHAR(10) not null default);-- 两个约束并排写7SELECT*from boy;8INSERT into boy VALUES(,"小男孩",18,"篮球","日本广岛");-- id自动增长9INSERT into boy VALUES(2,"胖子",16,"羽毛球","日本长崎");10INSERT into boy VALUES(,"三上悠亚",16,"足球","日本");11INSERT into boy VALUES(4,"苍井空",30,"排球","日本");12INSERT into boy VALUES(,"小泽美亚",16,"排球","日本长崎"); 外键约束
概念:
外键用来让两个表的数据之间建立连接,保证数据的一致性和完整性
注意:在从表添加外键约束的时候,主表必须要已经建立好,插入数据也一样,必须把主表完整的建立好才能建立一个与主表进行关联的从表
xxxxxxxxxx21create table rg(id int(2),name varchar(8),age int(3),dep_id int(2));-- 建立一个员工表2create table dept(id int(2),dept_name varchar(8),addr varchar(8));-- 建立一个部门表语法:
添加约束
xxxxxxxxxx81-- 创建表时添加外键约束2create table 表名(3列名 数据类型,4...5[constraint] [外键名称] foreign key(外键列名) references 主表(主要列名)6);7-- 建表后添加外键约束8alter table 表名 add constraint 外键名称 foreign key (外键字段名) references 主表名称(主表列名);例子(建表的时候添加外键约束)
xxxxxxxxxx171-- 创建emp表(从表)2create table emp(3id int(3) PRIMARY KEY ,4nam varchar(5),5age int(3),6dep_id int(2),7-- 创建外键dep_id关联dept 上的id 注意,必须要先创建主表dept,添加数据的时候也是先添加主表的数据8-- 外键的名称是fk_emp_dept9CONSTRAINT fk_emp_dept FOREIGN KEY(dep_id) REFERENCES dept(id)10);11-- 创建dept表(主表)12create table dept(id int(3) PRIMARY KEY,dep_name varchar(8),addr VARCHAR(8));13-- 插入emp数据14insert into emp VALUES(1,'LiLi',18,1),(2,'ZhSan',19,1),(3,'LiSi',17,2),(4,'Tony',20,2);1516-- 插入dept数据17insert into dept VALUES(1,'研发部','广州'),(2,'管理部','深圳');删除约束
xxxxxxxxxx11alter table 从表(外键是在从表里面创建的)表名 drop foreign key 外键名称(在从表创建外键的时候就自定义了一个外键的名称);
数据库设计
软件的研发步骤
数据库设计概念
数据库设计就是根据业务系统的具体需求,结合我们所选用的DBMS,为这个业务系统构造出最优的数据存储过程
建立数据库中的表结构以及表与表之间的关联关系的过程
有哪些表?表里面有哪些字段?表与表之间有什么关系?
数据库设计步骤
需求分析——数据是什么?数据具体有哪些属性?数据与属性的特点是什么?
逻辑分析——通过ER图对数据库进行逻辑建模,不需要考虑我们所选的数据库管理系统
物理设计——根据数据库自身的特点把逻辑设计转化为物理设计
维护设计——1、对新的需求进行建表;2、表优化。
表关系之一对多
如:部门对员工
一个部门对应多个员工,一个员工对应一个部门
实现方式——在多的一方建立一个外键,指向一方的主键
表关系之多对多
如:商品和订单
一个商品对应多个订单,一个订单包含多个商品
实现方式——建立第三张中间表,中间表至少包含有两个外键,分别是关联两方主键
表关系之一对一
一般用于表的拆分
如:用户与用户
一对一关系多用于表的拆分,将一个实体中经常使用的字段放一张表,不经常使用的字段放另一张表,用于提高查询性能
实现方式:在任意一方加入外键,关联另一方主键,并且设置外键为唯一约束(unique)——类似于一对多,但是多出一个唯一外键
数据库设计总结
数据库设计设计什么
有哪些表
表里有哪些字段
表和表之间有什么关系
表关系有哪些种
一对一
一对多
多对多
数据库设计案例
xxxxxxxxxx121use 专辑;2show tables;3create table 曲目...4create table 评论...5create table 用户...6create table 专辑...7create table 用户专辑...8alter table 曲目 add constraint 曲目_专辑 foreign key (专辑) references 专辑(nam);9alter table 评论 add constraint 评论_专辑 foreign key (专辑) references 专辑(nam);10alter table 评论 add constraint 评论_用户 foreign key (用户名) references 用户(用户名);11alter table 用户专辑 add constraint 专辑_用户 foreign key (用户名) references 用户(用户名);12alter table 用户专辑 add constraint 用户_专辑 foreign key (专辑) references 专辑(nam);
多表查询
多表查询
select *from 表1,表2...——这样写的会长生一个问题——笛卡尔积(有a、b两个集合,取a、b所有的组合情况就形成笛卡尔积)
需要消除无效的数据
`**select*from 表1,表2 where …**
xxxxxxxxxx11select * from tbale1,table2 where id1=id2 and nam1=name2;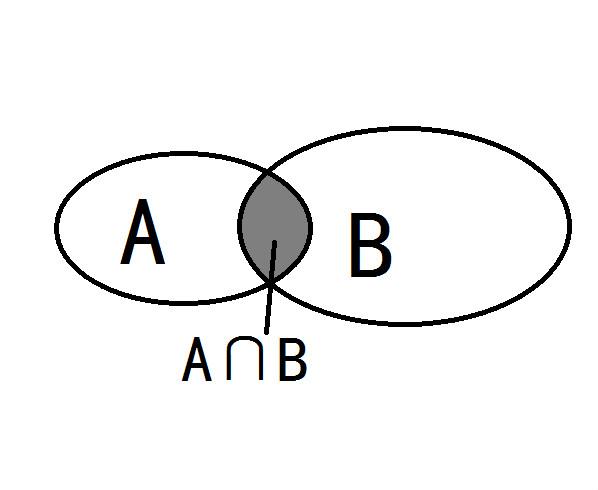
从多张表查询数据
多表查询分类:
连接查询
内连接——相当于查询A、B表交集部分数据
外连接
左外连接——相当于查询A表所有数据和交集部分数据
右外连接——相当于查询B表所有数据和交集部分数据
子查询
内连接查询
语法
xxxxxxxxxx51-- 隐式内连接2select 字段列表 from 表1,表2...where 条件;34-- 显示内连接5select 字段列表 from 表1 [inner] join 表2 on 条件;
外连接查询
外连接查询语法
xxxxxxxxxx41-- 左外连接2select 字段列表 from 表1 left [outer] join 表2 on 条件;3-- 右外连接4select 字段列表 from 表1 right [outer] join 表2 on 条件;
子查询
子查询概念:
查询中嵌套查询,称嵌套查询为子查询
子查询根据查询结果不同,作用不同:
单行单列:作为条件值,使用 = !=><等进行条件判断
xxxxxxxxxx11select 字段列表 from 表 where 字段名 = (子查询);多行单列:作为条件值,使用in等关键字进行条件判断
xxxxxxxxxx11select 字段列表 from 表 where 字段名 in (子查询);多行多列:作为虚拟表
xxxxxxxxxx11select 字段列表 from (子查询) where 条件;
事务
事务简介
数据库的事物是一种机制,一个操作序列,包含了一组数据库操作命令
事物把所有的命令作为一个整体一起向系统提交或撤销操作请求,即这一组数据库命令行要么同时成功要么同时失败
事物是一个不可分割的工作逻辑单元
事务操作5
开启事物——begin
提交事物——commit
回滚事物——rollback
事务四大特征
原子性(Atomicity):事物是不可分割的最小操作单位,要么同时成功要么同时失败
一致性(Consistency):事物完成时,必须使所有的数据都保持一致状态
隔离性(lsolation):多个事物之间,操作的可见性
持久性(Durability):事物一旦提交或回滚,它对数据库中的数据的改变就是永久的
MYSQL的事务是默认自动提交的
查询事物的默认提交方式:
select @@autocommit;——如果值是0手动提交,为1是自动提交